WEB API接口 大都是基于 HTTP协议的,首先要了解 HTTP 协议的基础知识
HTTP协议简介
HTTP 协议全称是超文本传输协议, 英文是Hypertext Transfer Protocol 。
HTTP 最初是用来在浏览器和网站服务器(web服务)之间传输超文本(网页、视频、图片等)信息的。
由于HTTP简洁易用,后来,不仅仅是浏览器和服务器之间使用它, 服务器和服务器之间, 手机App和服务器之间, 都广泛的采用。 成了一个软件系统间通信的首选协议 之一。
HTTP 有好几个版本,包括: 0.9、1.0、1.1、2,当前最广泛使用的是HTTP/1.1 版本。
HTTP 协议最大的特点是 通讯双方分为客户端和服务端 。
由于目前HTTP是基于TCP 协议的, 所以要进行通讯,客户端必须先和服务端创建 TCP 连接。
而且 HTTP 双方的信息交互,必须是这样一种方式:
客户端 先发送 http请求(request)给 服务端
然后服务端 发送 http响应(response)给 客户端
特别注意:HTTP协议中,服务端不能主动先发送信息给 客户端。
而且在1.1 以前的版本, 服务端 返回响应给客户端后,连接就会 断开 ,下一次双方要进行信息交流,必须重复上面的过程,重新建立连接,客户端发送请求,服务返回响应。
到了 1.1 版本, 建立连接后,这个连接可以保持一段时间(keep alive), 这段时间,双方可以多次进行 请求和响应, 无需重新建立连接。
如果客户端是浏览器,如何在chrome浏览器中查看 请求和响应的HTTP消息,请参考视频讲解
HTTP请求消息
下面是2个http请求消息的示例
GET /mgr/login.html HTTP/1.1 Host: www.baiyueheiyu.com User-Agent: Mozilla/6.0 (compatible; MSIE5.01; Windows NT) Accept-Language: zh-cn Accept-Encoding: gzip, deflate
POST /api/medicine HTTP/1.1 Host: www.baiyueheiyu.com User-Agent: Mozilla/6.0 (compatible; MSIE5.01; Windows NT) Content-Type: application/x-www-form-urlencoded Content-Length: 51 Accept-Language: zh-cn Accept-Encoding: gzip, deflate name=qingmeisu&sn=099877883837&desc=qingmeisuyaopin
http请求消息由下面几个部分组成
请求行 request line
是http请求的第一行的内容,表示要操作什么资源,使用的 http协议版本是什么。
里面包含了3部分信息: 请求的方法,操作资源的地址, 协议的版本号
例如
GET /mgr/login.html HTTP/1.1
表示要 获取 资源, 资源的 地址 是 /mgr/login.html , 使用的 协议 是 HTTP/1.1
而
POST /api/medicine HTTP/1.1
表示 添加 资源信息, 添加资源 到 地址 /api/medicine , 使用的 协议 是 HTTP/1.1
GET、POST是请求的方法,表示这个动作的大体目的,是获取信息,还是提交信息,还是修改信息等等
常见的HTTP 请求方法包括:
- GET
从服务器 获取 资源信息,这是一种最常见的请求。
比如 要 从服务器 获取 网页资源、获取图片资源、获取用户信息数据等等。
- POST,请求方法就应该是
添加 资源信息 到 服务器进行处理(例如提交表单或者上传文件)。
比如 要 添加用户信息、上传图片数据 到服务器 等等
具体的数据信息,通常在 HTTP消息体中, 后面会讲到
- PUT
请求服务器 更新 资源信息 。
比如 要 更新 用户姓名、地址 等等
具体的更新数据信息,通常在 HTTP消息体中, 后面会讲到
- DELETE
请求服务器 删除 资源信息 。
比如 要 删除 某个用户、某个药品 等等
HTTP还有许多其他方法,比如 PATCH、HEAD 等,不是特别常用,暂且不讲。
请求头 request headers
请求头是http请求行下面的 的内容,里面存放 一些 信息。
比如,请求发送的服务端域名是什么, 希望接收的响应消息使用什么语言,请求消息体的长度等等。
通常请求头 都有好多个,一个请求头 占据一行
单个请求头的 格式是: 名字: 值
HTTP协议规定了一些标准的请求头,点击查看MDN的描述
开发者,也可以在HTTP消息中 添加自己定义的请求头
消息体 message body
请求的url、请求头中 可以存放 一些数据信息, 但是 有些数据信息,往往需要 存放在消息体中。
特别是 POST、PUT等请求,添加、修改的数据信息 通常都是 存放在 请求消息体 中的。
如果 HTTP 请求 有 消息体, 协议规定 需要在 消息头和消息体 之间 插入一个空行, 隔开 它们。
请求消息体中保存了要提交给服务端的数据信息。
比如:客户端要上传一个文件给服务端,就可以通过HTTP请求发送文件数据给服务端。
文件的数据 就应该在请求的消息体中。
再比如:上面示例中 客户端要添加药品,药品的名称、编码、描述,就存放在请求消息体中。
WEB API 请求消息体 通常是某种格式的文本,常见的有
- Json
- Xml
- www-form-urlencoded
HTTP响应消息
下面是1个http响应消息的示例
HTTP/1.1 200 OK Date: Thu, 19 Sep 2019 08:08:27 GMT Server: WSGIServer/0.2 CPython/3.7.3 Content-Type: application/json Content-Length: 37 X-Frame-Options: SAMEORIGIN Vary: Cookie {"ret": 0, "retlist": [], "total": 0}
HTTP响应消息包含如下几个部分
状态行 status line
状态行在第一行,包含3个部分:
- 协议版本
上面的示例中,就是 HTTP/1.1
- 状态码
上面的示例中,就是 200
- 描述状态的短语
上面的示例中,就是 OK
我们重点来看一下状态码,它表示了 服务端对客户端请求的处理结果 。
状态码用3位的数字来表示,第一位 的 数字代表 处理结果的 大体类型,常见的有如下几种:
• 2xx
通常 表示请求消息 没有问题,而且 服务器 也正确处理了
最常见的就是 200
• 3xx
这是重定向响应,常见的值是 301,302, 表示客户端的这个请求的url地址已经改变了, 需要 客户端 重新发起一个 请求 到另外的一个url。
• 4xx
表示客户端请求有错误, 常见的值有:
400 Bad Request 表示客户端请求不符合接口要求,比如格式完全错误
401 Unauthorized 表示客户端需要先认证才能发送次请求
403 Forbidden 表示客户端没有权限要求服务器处理这样的请求, 比如普通用户请求删除别人账号等
404 Not Found 表示客户端请求的url 不存在
• 5xx
表示服务端在处理请求中,发生了未知的错误。
通常是服务端的代码设计问题,或者是服务端子系统出了故障(比如数据库服务宕机了)
响应头 response headers
响应头 是 响应状态行下面的 的内容,里面存放 一些 信息。 作用 和 格式 与请求头类似,不再赘述。
消息体 message body
有时候,http响应需要消息体。
同样, 如果 HTTP 响应 有 消息体, 协议规定 需要在 消息头和消息体 之间 插入一个空行, 隔开 它们。
比如,白月SMS系统 请求 列出 药品 信息,那么 药品 信息 就在HTTP响应 消息体中
再 比如,浏览器地址栏 输入 登录网址,浏览器 请求一个登录网页的内容,网站服务器,就在响应的消息体中存放登录网页的html内容。
和请求消息体一样,WEB API 响应消息体 通常也是某种格式的文本,常见的有:
- Json
- Xml
- www-form-urlencoded
接口测试
通常说的接口测试(或者API接口测试),其实就是 对 软件系统 消息交互接口 的测试
消息交互接口 是 软件系统 和 其他软件系统 交互 的那部分。
接口测试就是
- 依据接口规范,写出测试用例,
- 使用软件工具,直接通过消息接口 对 被测系统 进行消息收发
- 验证被测系统行为是否正确。
接口测试,通常是对 服务端做的 比较多,但是也有对客户端做的。 关键是看 被测系统是 服务端还是客户端。
目前的软件系统之间的消息接口 大部分是 基于 HTTP 协议收发的。
HTTP协议的特点是,客户端发出一个HTTP请求给 服务端,服务端就返回一个HTTP响应。好像程序的API调用。
接口测试工具
基于 HTTP 的接口测试工具, 常见的 有 Postman、Jmeter等,
这些工具,都是用来 构建HTTP请求消息,并且解析收到的HTTP响应消息, 用户来判断是否符合预期。
熟悉 Python 语言的朋友, 也完全可以使用 requests 库,自己写代码发送接收HTTP请求,进行测试。
比如
import requests response = requests.get('https://www.google.com') print(response.text)
抓包工具 fiddler
在做接口测试的时候, 经常需要用到 抓包工具 ,来查看具体的发送的请求消息,和接收的响应消息。
fiddler 就是常用的一款 HTTP 抓包工具。
fiddler 是 代理式 抓包,启动后会启动一个代理服务器(同时设置自己作为系统代理),监听在 8888 端口上。
HTTP客户端需要设置 fiddler 作为代理, 把HTTP请求消息 发送给 fiddler, fiddler再转发HTTP消息给服务端。
服务端返回消息也是先返回给 fiddler,再由fiddler转发给 客户端。
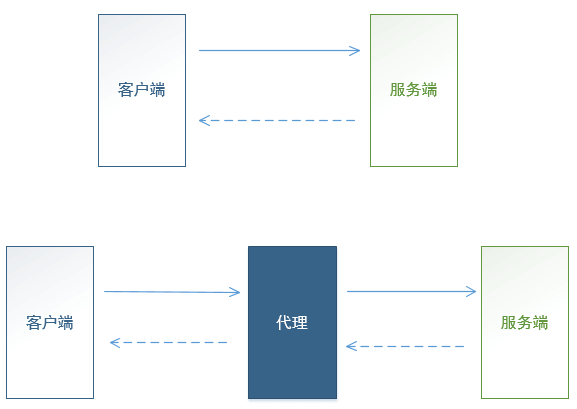
这样,请求响应消息都经过了 fiddler,fiddler自然就抓到了 HTTP请求和响应,可以展示出来给大家查看。
安装好以后,通常我们需要设置一下抓包过滤项,否则抓到的包太多,不方便分析。
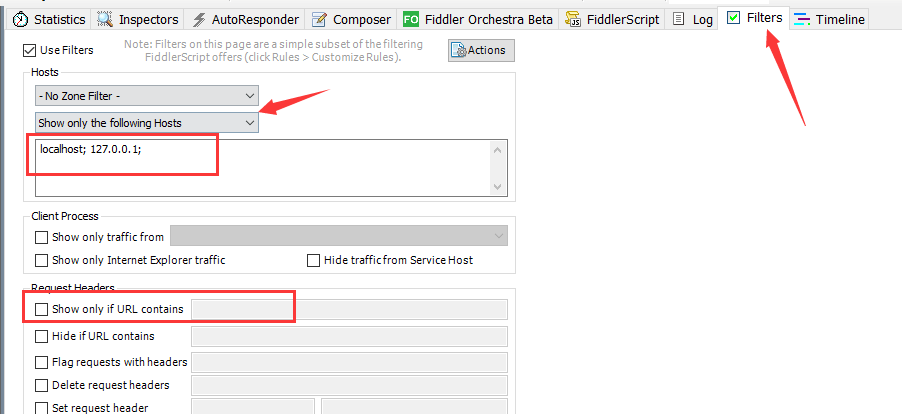
要 根据目标主机地址过滤 HTTP消息, 在上图所示 左边的红色箭头处, 选择 show only the following hosts。
然后,在下边的方框,里面填写要抓取的HTTP消息的目标地址, 可以使用* 作为通配符。
localhost; 127.0.0.1;*.sohu.com
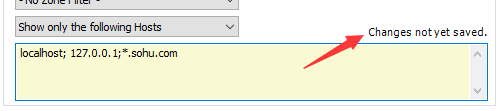
注意:修改完设置后,一定要点击一下 下图箭头所示处,才能保存生效。
抓到包后,点击左边列表框内你要查看的 HTTP消息 ,
然后再点击右边 标签栏里面的 Inspectors 标签,即可进行查看。
右边 上半区 对应的请求消息的内容, 右边下半区对应的是响应消息的内容。
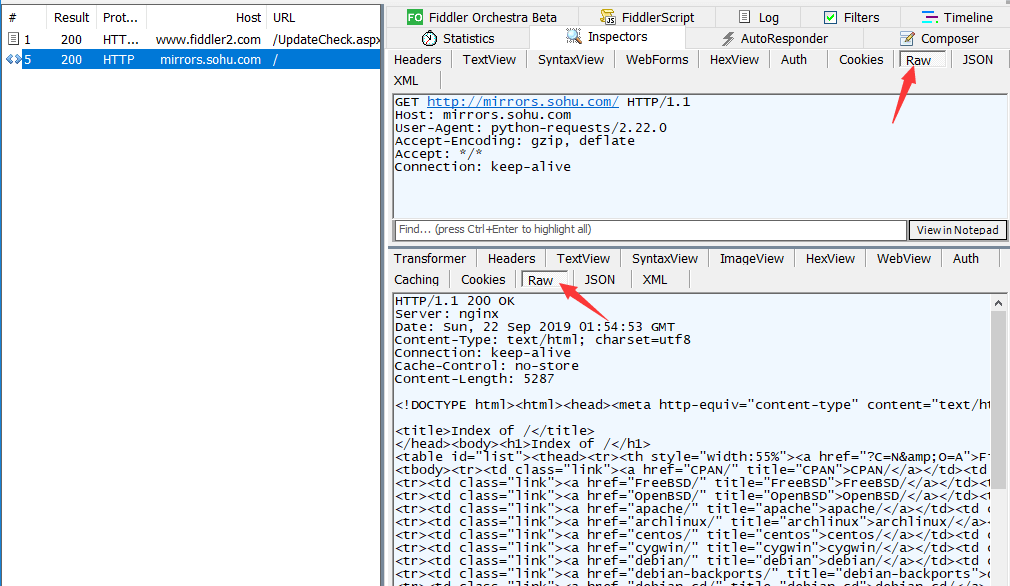
点击 上半区 和 下半区的 raw 标签,可以查看整个 HTTP请求和响应的具体内容。
安装好以后,要抓到 HTTP 包,必须设置好客户端,让客户端使用 fiddler作为代理。
浏览器抓包
浏览器可以通过其代理配置,指定使用fiddler作为代理,从而让fiddler抓到包。
但是浏览器本身F12打开的开发者窗口,就可以很方便的看到HTTP消息,所以不需要fiddler抓包。
requests程序抓包
要让requests 发送请求使用代理,只需要如下参数进行设定即可
import requests proxies = { 'http': 'http://127.0.0.1:8888', 'https': 'http://127.0.0.1:8888', } response = requests.get('http://mirrors.sohu.com/', proxies=proxies) print(response.text)
构建HTTP请求
构建请求URL参数
什么是url参数?
https://www.baidu.com/s?wd=iphone&rsv_spt=1
问号后面的部分 wd=iphone&rsv_spt=1 就是 url 参数,
每个参数之间是用 & 隔开的。
上面的例子中 有两个参数 wd 和 rsv_spt, 他们的值分别为 iphone 和 1 。
url参数的格式,有个术语叫 urlencoded 格式。
使用Requests发送HTTP请求,url里面的参数,通常可以直接写在url里面,比如
response = requests.get('https://www.baidu.com/s?wd=iphone&rsv_spt=1')
但是有的时候,我们的url参数里面有些特殊字符,比如 参数的值就包含了 & 这个符号。
那么我们可以把这些参数放到一个字典里面,然后把字典对象传递给 Requests请求方法的 params 参数,如下
urlpara = { 'wd':'iphone&ipad', 'rsv_spt':'1' } response = requests.get('https://www.baidu.com/s',params=urlpara)
构建请求消息头
有时候,我们需要自定义一些http的消息头
每个消息头也就是一种 键值对的格式存放数据,如下所示
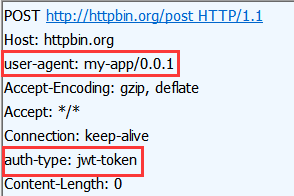
user-agent: my-app/0.0.1 auth-type: jwt-token
Requests发送这样的数据,只需要将这些键值对的数据填入一个字典。
然后使用post方法的时候,指定参数 headers 的值为这个字典就可以了,如下
headers = { 'user-agent': 'my-app/0.0.1', 'auth-type': 'jwt-token' } r = requests.post("http://httpbin.org/post", headers=headers) print(r.text)
如果我们用工具抓包就可以发现 发送的http请求如下
构建请求消息体
当我们进行API 接口测试的时候, 根据接口规范,构建的http请求,通常需要构建消息体。
http 的 消息体就是一串字节,里面包含了一些信息。这些信息可能是文本,比如html网页作为消息体,也可能是视频、音频等信息。
消息体可能很短 ,只有一个字节, 比如字符 a。 也可能很长,有几百兆个字节,比如一个视频文件。
最常见的消息体格式当然是 表示网页内容的 HTML。
Web API接口中,消息体基本都是文本,文本的格式主要是这3种: urlencoded ,json , XML。
注意:消息体采用什么格式,是由 开发人员设计的决定的
XML 格式消息体
前面说了,消息体就是存放信息的地方,信息的格式完全取决设计者的需要。
如果设计者决定用 XML 格式传输一段信息,用Requests库,只需要这样
payload = ''' <?xml version="1.0" encoding="UTF-8"?> <WorkReport> <Overall>良好</Overall> <Progress>30%</Progress> <Problems>暂无</Problems> </WorkReport> ''' r = requests.post("http://httpbin.org/post",data=payload.encode('utf8')) print(r.text)
Requests库的post方法,参数data指明了,消息体中的数据是什么。
如果传入的是字符串类型,Requests 会使用缺省编码 latin-1 编码为字节串放到http消息体中,发送出去。
而上面的例子里面包含中文,不能用缺省 latin-1编码.
所以我们将字符串对象,用 utf8 编码为字节串对象Bytes 传入给data参数,Requests就会直接把这个字符串放到 http消息体中,发送出去。
如果作为系统开发的设计者,觉得发送这样一篇报告,只需要核心信息就可以了,不需要这样麻烦的XML格式,也可以直接用纯文本,像这样
payload = ''' report Overall:良好 Progress: 30% Problems:暂无 ''' r = requests.post("http://httpbin.org/post", data=payload.encode('utf8')) print(r.text)
所以,如果就是一些字符信息,我们可以自行构建任何消息体格式。
但是采用 xml、json 这样的标准格式,可以很好的表示复杂的信息数据,
比如,我们要传递的工作报告里面,存在的问题有 多个,用 XML 就可以这样表示
<?xml version="1.0" encoding="UTF-8"?> <WorkReport> <Overall>良好</Overall> <Progress>30%</Progress> <Problems> <problem no='1'> <desc>问题1....</desc> </problem> <problem no='2'> <desc>问题2....</desc> </problem> </Problems> </WorkReport>
而且 编程语言都有现成的库处理解析 XML、json 这样的数据格式,我们直接拿来使用,非常方便。
而自己定义的格式就难以表达这样复制的数据格式,而且还要自己写代码在发送前进行格斯转化,接收后进行格式解析,非常麻烦。
urlencoded 格式消息体
这种格式的消息体就是一种 键值对的格式存放数据,如下所示
key1=value1&key2=value2
Requests发送这样的数据,当然可以直接把这种格式的字符串传入到data参数里面。
但是,这样写的话,如果参数中本身就有特殊字符,比如等号,就会被看成参数的分隔符,就麻烦了。
我们还有更方便的方法:只需要将这些键值对的数据填入一个字典。
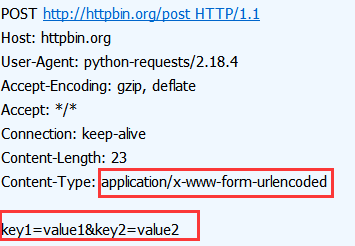
然后使用post方法的时候,指定参数 data 的值为这个字典就可以了,如下
payload = {'key1': 'value1', 'key2': 'value2'} r = requests.post("http://httpbin.org/post", data=payload) print(r.text)
如果我们用工具抓包就可以发现 发送的http请求如下
json 格式消息体
json 格式 当前被 Web API 接口广泛采用。
json 是一种表示数据的语法格式。 它和Python 表示数据的语法非常像。
比如要表示上面的报告信息,可以这样
{ "Overall":"良好", "Progress":"30%", "Problems":[ { "No" : 1, "desc": "问题1...." }, { "No" : 2, "desc": "问题2...." } ] }
它的优点是:比xml更加简洁、清晰, 所以程序处理起来效率也更高。
也可以将 数据对象 直接 传递给post方法的 json参数,如下
r = requests.post("http://httpbin.org/post", json={...})
session机制
原理
我们来思考一个问题。
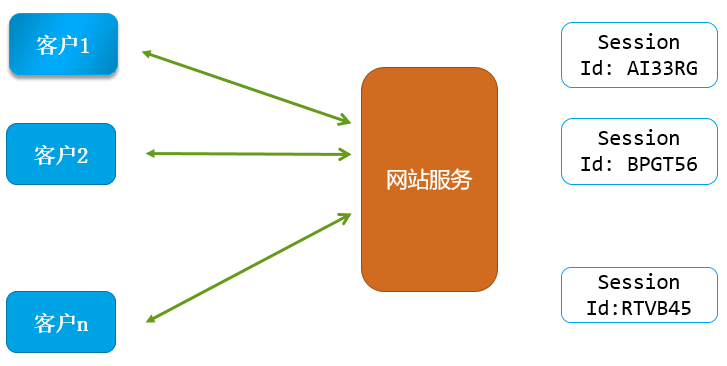
一个网站,比如一个购物网站,服务成千上万的客户。
这么多客户同时访问网站,挑选商品,购物结算,都是通过HTTP请求访问网站的。
这个网站服务程序 怎么每个HTTP请求(比如付费 HTTP 请求)对应的是哪个客户的呢?
网站是怎么做到这点的呢?
一种常见的方式就是:通过 Session机制
session 翻译成中文就是 会话 的意思
session 机制大体原理如下图所示 :
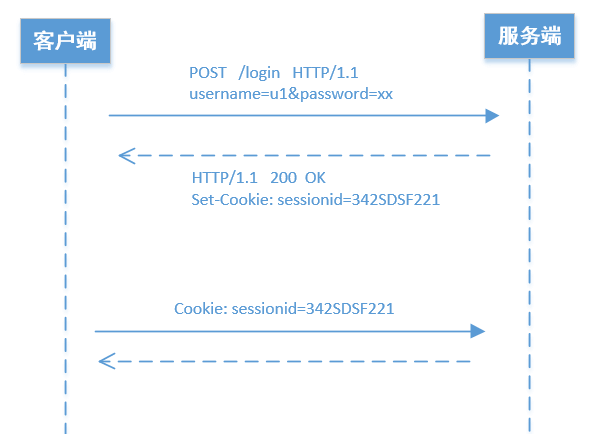
用户使用客户端登录,服务端进行验证(比如验证用户名、密码)。
验证通过后,服务端系统就会为这次登录创建一个session。
session就是一个数据结构,保存该客户这次登录操作相关信息。通常保存在数据库中。
同时创建一个唯一的sessionid(就是一个字符串),标志这个session。
然后,服务端通过HTTP响应,把sessionid告诉客户端。
客户端在后续的HTTP请求消息头中,都要包含这个sessionid。这样服务端就会知道,这个请求对应哪个session,从而知道对应哪个客户。
从上图可以看出, 服务端是通过 HTTP的响应头 Set-Cookie 把产生的 sessionid 告诉客户端的。
客户端的后续请求,是通过 HTTP的请求头 Cookie 告诉服务端它所持有的sessionid的。
cookie 英文就是小甜饼的意思,这里表示一小段数据。
HTTP 协议规定了, 网站服务端放HTTP响应中 消息头 Set-Cookie 里面的数据, 叫做 cookie 数据, 浏览器客户端 必须保存下来。
而且后续访问该网站,必须在 HTTP的请求头 Cookie 中携带保存的所有cookie数据。
requests处理session-cookie
我们在Python代码中如果接收到服务端HTTP响应,其中Set-Cookie的数据怎么保存呢? 后续怎样放到请求消息头中 Cookie中呢?
前面 学过 HTTP响应中 如何 获取响应头, 构建请求怎样设置请求头,完全可以自己处理。
而且,requests库给我们提供一个 Session 类 。
通过这个类,无需我们操心, requests库自动帮我们保存服务端返回的 cookie数据, HTTP请求自动 在消息头中放入 cookie 数据。
如下所示:
import requests # 打印HTTP响应消息的函数 def printResponse(response): print('\n\n-------- HTTP response * begin -------') print(response.status_code) for k, v in response.headers.items(): print(f'{k}: {v}') print('') print(response.content.decode('utf8')) print('-------- HTTP response * end -------\n\n') # 创建 Session 对象 s = requests.Session() # 通过 Session 对象 发送请求 response = s.post("http://127.0.0.1/api/mgr/signin", data={ 'username': 'byhy', 'password': '88888888' }) printResponse(response) # 通过 Session 对象 发送请求 response = s.get("http://127.0.0.1/api/mgr/customers", params={ 'action' : 'list_customer', 'pagesize' : 10, 'pagenum' : 1, 'keywords' : '', }) printResponse(response)
本文转载自白月黑羽,略作精简。
即使是最平凡的人,
也得要为他那个世界的存在而战斗。
从这个意义上说,
在这些平凡的世界里,
也没有一天是平静的。
《平凡的世界》
——路遥






评论
还没有任何评论,你来说两句吧!