前言
虽然之前更新了多篇shader相关的博文,但我对于渲染管线仍然处于一知半解的程度,今天就好好整理一下发出来。
什么是渲染管线
所谓管线(Pipeline),也叫做流水线,最早是应用在制造业工厂中,将一个产品从原料加工到成品,划分为多个独立的环节,每个环节分配给专门的人完成,这样在批量制作产品时,可以让所有环节并行运行,从而大幅提高生产效率,降低生产成本,并保证了产品的标准性。
而在计算机的图形渲染领域,这样的流水线就叫做渲染管线,是用来将模型、贴图、shader等数据由CPU和GPU通过多个环节的并行计算,最终得到输出图像的工作过程。
渲染管线并不是一成不变的,根据使用的三维软件以及硬件平台的不同,内部实现细节会有一定的差别,下面就以Unity内部的渲染管线为例进行介绍。
下图就是是Unity中的渲染管线的简图,说明了从渲染开始到图像输出到屏幕上之间的大致步骤。
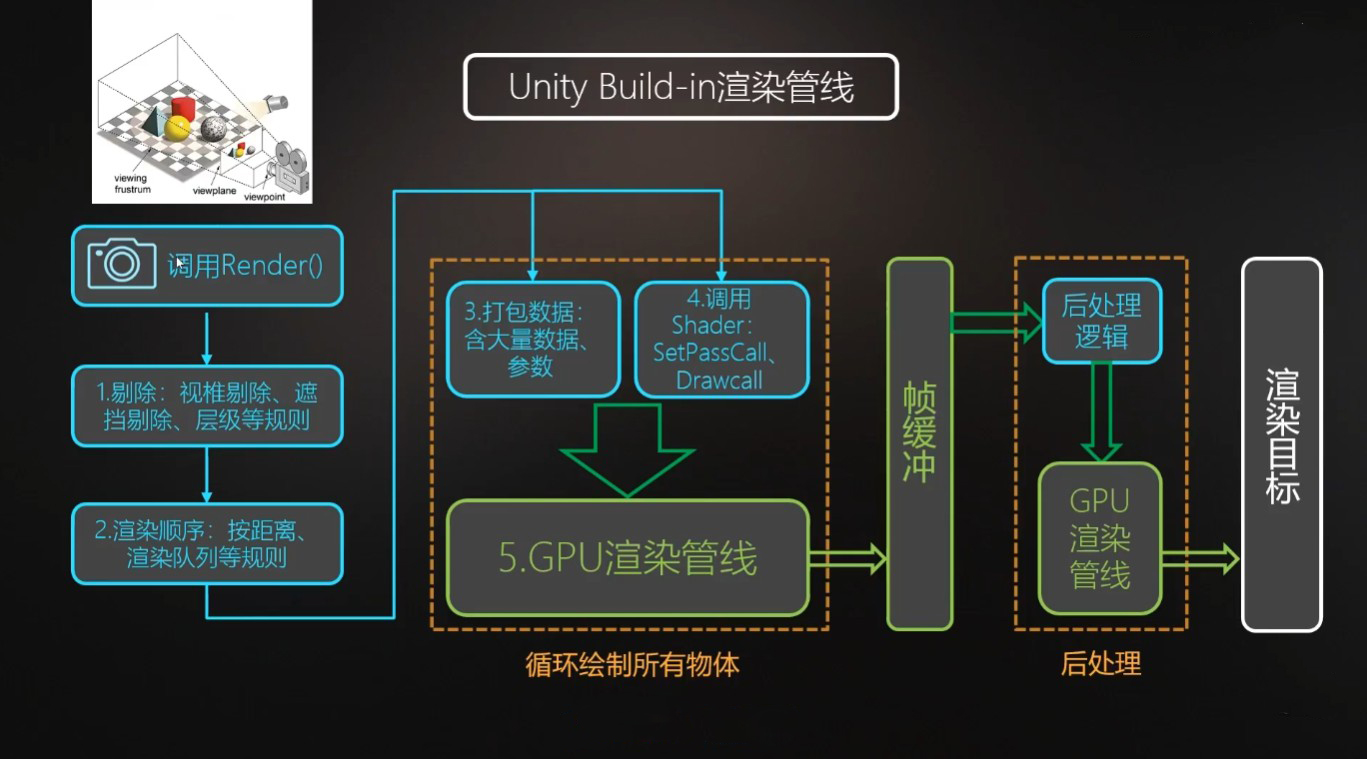
蓝色部分由CPU负责计算,绿色部分则是GPU负责计算,其中GPU渲染管线大致步骤如下。
从概念上来说,整个渲染管线大致分为应用阶段、几何阶段、光栅化阶段、后处理这四个大的阶段,下面会逐一进行介绍。
应用阶段
应用阶段包括GPU渲染管线前的CPU处理阶段,主要是用于为GPU准备需要使用的数据。
剔除(Culling)
剔除有视锥体剔除(Frustum Culling)、层级剔除(Layer Culling Mask)、遮挡剔除(Occlusion Culling)等步骤,目的是将不想被摄像机看到的物体剔除掉,减少不必要的性能开销,提高渲染效率。
视锥体剔除
在Unity中,摄像机的可视区域是一个横放的金字塔形称为视锥体,由近裁面、远裁面、视场角三个参数控制,通过计算这个视锥体与场景中的模型是否相交,没有相交就说明位于可视区域外,这样的模型就应该进行剔除。
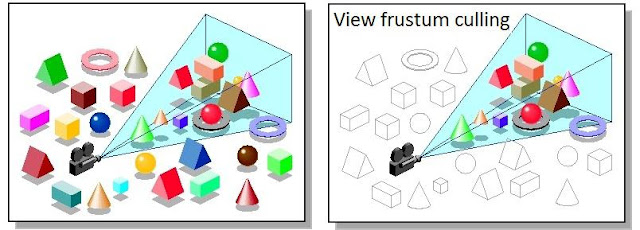
由于模型一般面数较多,因此会采用给模型创建包围体再计算包围体与可视区域是否相交的方式简化计算。包围体有多种计算方法,常用的有OBB(Oriented Bounding Box,有向包围盒)、AABB(Axis-Aligned Bounding Box,轴对齐包围盒)、球形包围体(外接球)等,其中AABB因为计算方便而更为常用。

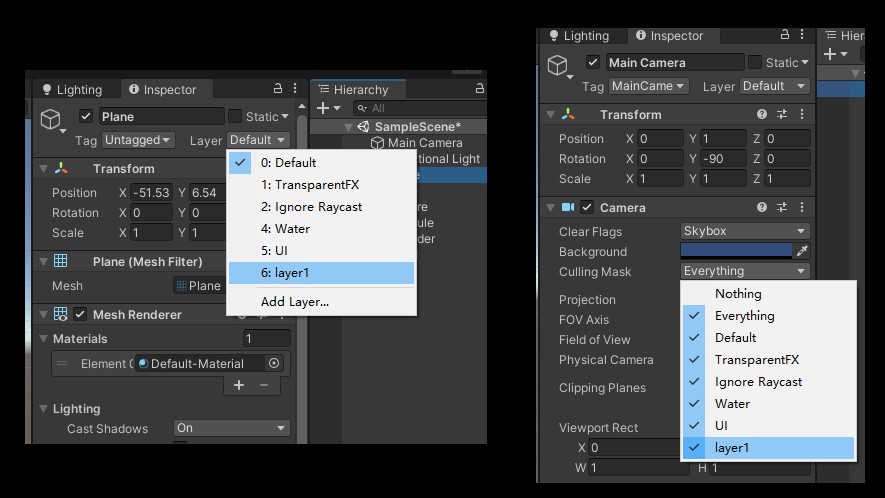
层级剔除
Unity中的模型可以设置自身所处的层级(Layer),而摄像机则可以设置需要剔除掉的层级,从而跳过特定物体的渲染。
遮挡剔除
在渲染时,如果物体有前后顺序并且后方的物体完全被前方物体遮挡住,此时后方物体在摄像机中完全看不见,也就没有必要进行计算,可以进行剔除。
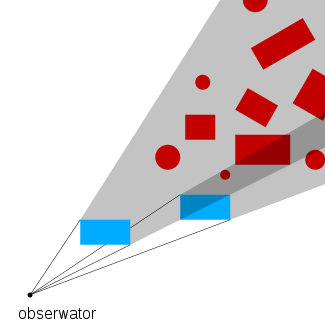
排序(Sort)
在剔除掉不需要渲染的物体后,还需要对场景中的物体进行排序,用于确定物体渲染的顺序。
在Unity中,排序是通过渲染队列(Render Queue)从小到大排列,越小越优先进行渲染,在shader中可以设置渲染队列的数值 。
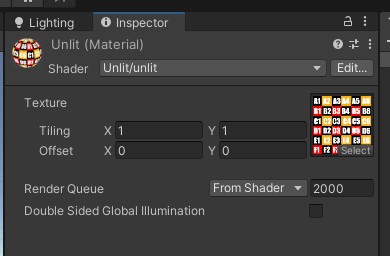
默认情况下各种物体的渲染队列如下:
- Background(1000)——最早被渲染的物体的渲染队列,用于背景。
- Geometry(2000)——不透明物体的渲染队列,Unity Shader中默认的渲染队列,大多数物体都应该用此队列渲染。
- AlphaTest(2450)——有透明通道,需要进行Alpha Test的物体的渲染队列。
- Transparent(3000)——半透明物体的渲染队列,用于Blend半透明混合等。
- Overlay(4000)——最后被渲染的物体的渲染队列,一般是覆盖效果,比如物体光晕、屏幕贴片等。
也可以手动设置为其他队列值,例如Tags { “Queue” = “Background+1”}等。
其中不透明物体的渲染队列小于2500,相同时按到摄像机的距离从前到后排序,半透明物体的渲染队列大于2500,相同时按距到摄像机的距离从后到前排序,保证不透明物体先于半透明物体渲染。
对不透明物体来说,前方物体会遮挡后方物体,后方物体被遮挡的部分不需要渲染,被遮挡的部分顶点会在后面的环节中被剔除掉,因此前方物体优先;而对于半透明物体来说,前后物体都需要渲染,并且后方物体需要优先渲染,再渲染前方物体叠加到后方物体上,否则会因为透明排序错误导致透明效果异常,因此后方物体优先。
打包数据(Batch)
在完成上一步排序后,CPU会依次将模型模型信息、变换矩阵、灯光材质等数据打包传入GPU。
其中模型信息包括顶点坐标、法线、UV、切线、顶点色、索引列表(Indices Array)等;变换矩阵包括世界变换矩阵、VP矩阵(根据摄像机位置和fov等参数构建)等;灯光材质参数包括Shader、材质参数、纹理贴图、灯光信息等。
调用(Call)
在把打包好的数据发送给GPU时,会调用两个指令:SetPass Call和Draw Call。
其中SetPass Call用于设置各种渲染状态,例如告诉GPU使用哪个Shader、哪种混合模式,是否进行背面剔除等。Shader脚本中一个Pass语义块就是一个完整的渲染流程,一个Shader可以包含多个Pass语义块,每当GPU运行一个Pass之前,就会产生一个SetPassCall,所以可以理解为调用一个完整渲染流程。
Draw Call则是CPU每次调用图像编程接口命令GPU渲染的操作。Draw Call就是一次渲染命令的调用,它指向一个需要被渲染的图元(primitive)列表,不包含任何材质信息。GPU收到指令就会根据渲染状态(例如材质、纹理、着色器等)和所有输入的顶点数据来进行计算,最终输出成屏幕上显示的像素。
每次调用Draw Call前,CPU都会向GPU发送很多数据,这个过程是很慢的,因此Draw Call多了,就会导致GPU一直在等待CPU发送信息,GPU的性能就会浪费。很多优化不好的游戏之所以能让旗舰显卡和中端显卡众生平等,就是因为没有优化好Draw Call的调用。
而要减少Draw Call的数量,就可以将很多同样渲染状态的Draw Call进行批处理(Batching),合并成一个大的Draw Call,只不过这种合批更适合静态的物体,因为动态物体的合批每帧都需要重新合并再发送。
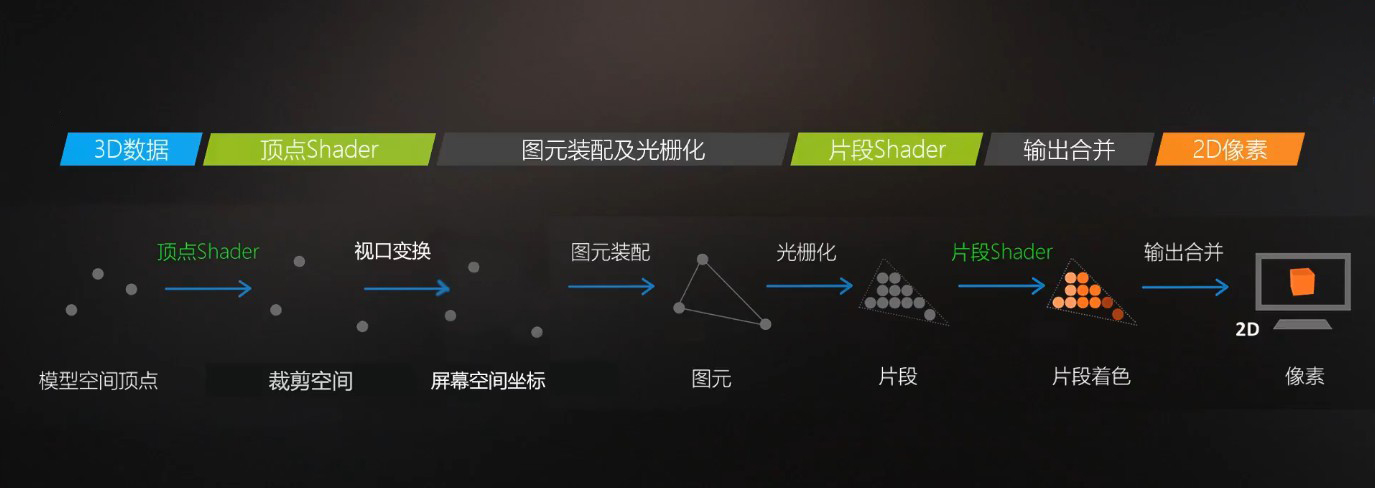
几何阶段
几何阶段包括GPU渲染管线中的顶点着色器以及屏幕映射部分,主要是对CPU传入的模型顶点进行逐顶点操作,并将顶点坐标变换为屏幕空间。
顶点着色器(Vertex Shader)
顶点着色器,顾名思义,每个从CPU发送到GPU的顶点都会调用一次顶点着色器进行处理。顶点着色器不能创建或删除顶点,也不能得到顶点之间的关系。
在顶点着色器中,GPU会将CPU发送过来的模型顶点坐标通过MVP变换矩阵从模型空间(Object Space)转换为裁剪空间(Clip Space),这样就完成了三维模型向二维屏幕投影的转换过程。
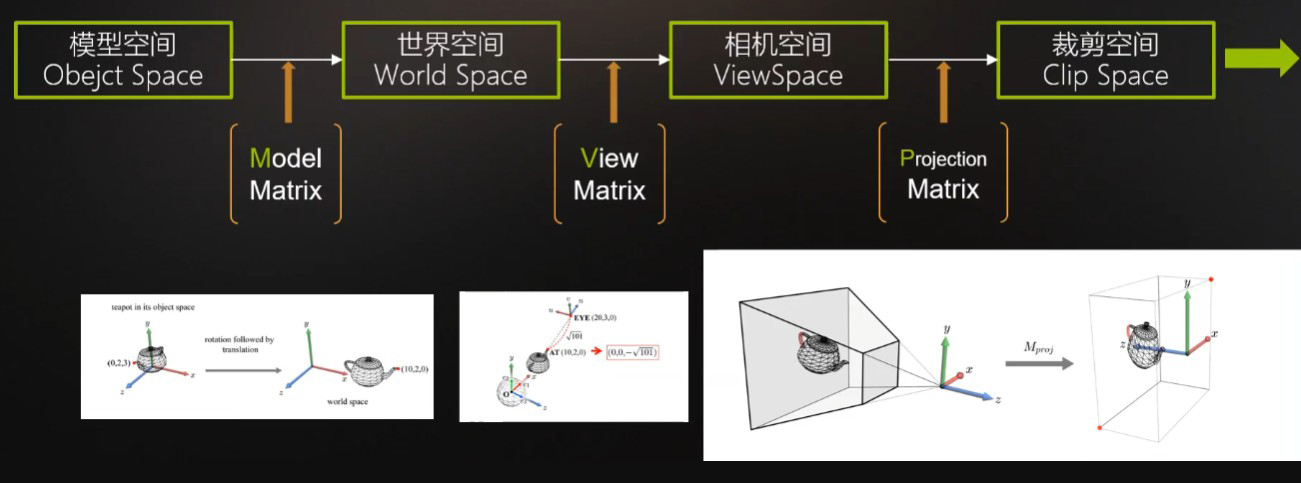
经过顶点着色器处理后,相机的金字塔形的视锥体会被转换变形为一个比例为2x2x1的立方体(CVV),内部的三维模型也会产生变形,从而形成透视效果。
除了进行坐标变换以外,顶点着色器还能对顶点色进行计算,或者制作顶点动画。
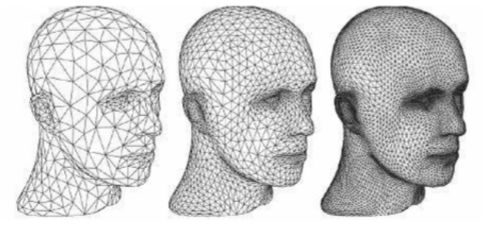
曲面细分着色器 (Tessellation Shader)
这是一个可选的着色器,主要是对三角面进行细分,以此来增加物体表面的三角面的数量。借助它可以实现细节层次(LOD,Level-of-Detail)的机制,使得离摄像机越近的物体具有更加丰富的细节,而远离摄像机的物体具有较少的细节,如下图所示。
屏幕映射
这个阶段的操作大多数是由硬件自动处理的,开发者无法完全控制,只能简单地的配置开放出来的选项,因此这一阶段又被称为硬件操作阶段。
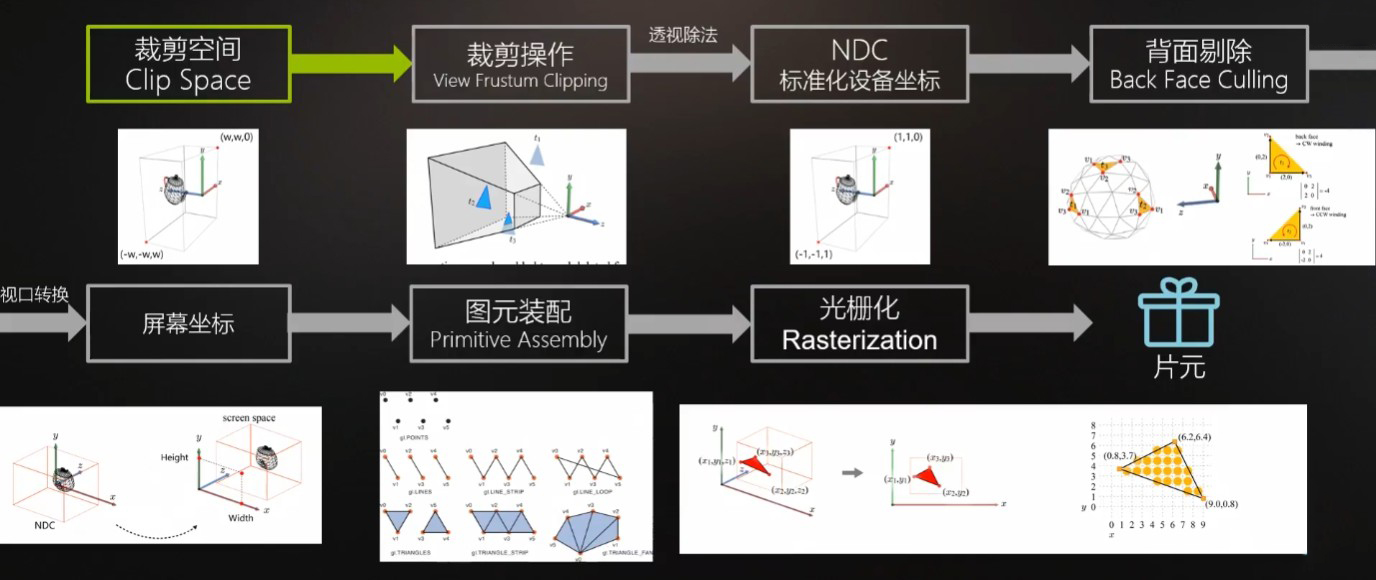
CPU阶段的剔除(Culling)是移除掉视锥体视野之外的模型,与视锥体相交的模型会被保留;而GPU阶段这里的裁剪操作(Clipping)则是对视锥体视野之外的顶点进行裁剪,与视锥体相交的三角面会被裁剪成新的三角面。
NDC标准化设备坐标则是将裁剪空间原来2W*2W*W的坐标范围归一化为2*2*1的坐标范围。
之后的背面剔除操作则是将背对着摄像机的三角面进行剔除,省去不必要的计算,也可以设置为剔除正面保留背面或者不进行剔除。
屏幕坐标映射(Screen Mapping)是将2*2*1的标准化坐标的x和y坐标,映射到屏幕的像素坐标上,而z坐标不进行修改用于之后计算片元的深度和遮挡关系。这样三维模型的点就投影到屏幕上了。
光栅化阶段
光栅化阶段包括图元装配、光栅化、片元着色器、逐片元操作等步骤。
图元装配(premitive Assembly)
在这一阶段,GPU会将转换完的顶点连接成线,组装成一个个三角形,这些三角形被称为图元,因此图元装配这一步骤又被称为三角形设置。
光栅化(Rasterization)
图元会被进一步处理,内部通过插值生成一个个类似像素的点(z坐标、顶点色、法线、切线、UV等都会被插值),区别于像素称为片元(Fragment),这一步骤又被称为三角形遍历。
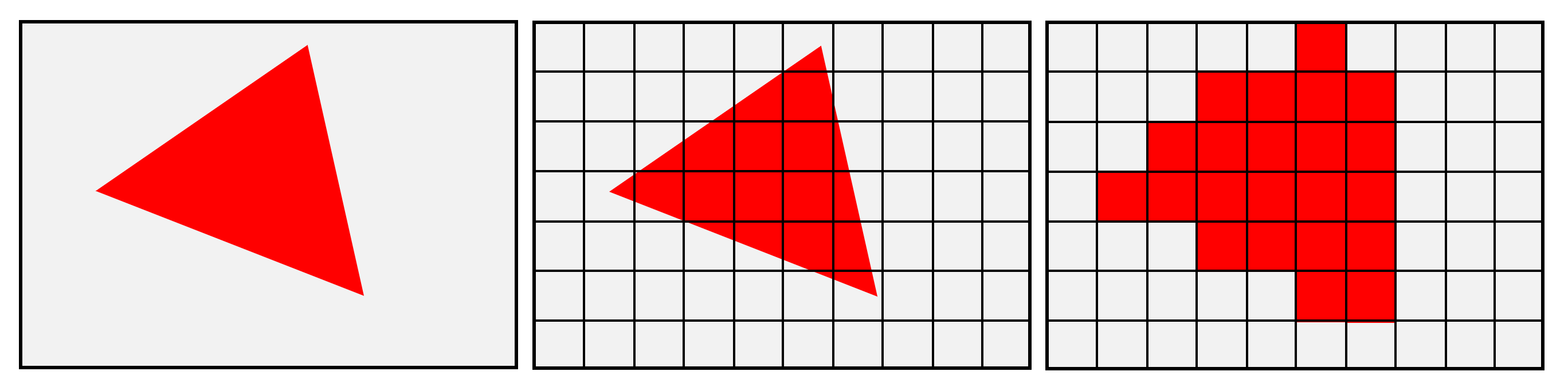
这一步就是光栅化操作,三维模型已经被彻底转换成了二维的图像,只是图像现在还没有上色。
片元着色器(Fragment Shader)
接下来对每个片元调用一次片元着色器,通过纹理采样(Texturing)和光照计算(Lighting)等完成片元的着色。
纹理采样指的是根据片元的UV坐标在纹理贴图上采集到对应像素的颜色的过程。
像素坐标取值范围是正整数,UV坐标映射得到的像素坐标则是浮点数,最简单的方式是通过近似找到距离最近的像素点作为采样的目标。
但是当纹理远小于对应模型区域的大小导致多个UV坐标映射到同一像素时,会产生锯齿和模糊问题,此时需要通过双线性插值等纹理过滤机制采样周围的像素进行特定的插值处理得到所需的像素颜色。

而在纹理尺寸远大于对应模型区域的大小时,会产生摩尔纹、锯齿等问题,此时可以通过Mipmap这种纹理链技术,将纹理贴图生成不同大小的一系列贴图,Level0为原图尺寸,Level1为二分之一尺寸,Level3为八分之一尺寸,以此类推,这样就可以根据模型映射区域的大小,自动选择合适大小的纹理进行采样。

这里特别说明一下,Mipmap因为需要保存多级别不同尺寸的贴图,会多消耗三分之一的存储空间。
UV默认的取值范围是[0, 1],对应纹理贴图上的像素数量,当UV坐标超过[0,1]范围时,需要决定纹理贴图的寻址模式。可以选择不重复、重复边缘、重复平铺纹理、重复并镜像纹理等方式。

纹理压缩则是将常见的图片格式压缩为各自硬件平台支持的压缩格式,尽量选择平台支持的细节损失较少而压缩比较大的压缩格式。
光照计算部分就是各种光照模型了,比如经典的由漫反射+高光反射+环境光组成的Phong光照模型。

再比如近年来广泛使用的PBR光照模型。

在设计光照模型时,要从直接光照和间接光照两部分考虑,其中直接光照的计算比较简单,间接光照可以通过Lightmap(光照贴图)、Reflection Probe反射球(Image Based Lighting基于图像的照明,镜面反射)、Light Probe(球谐光照SH)等方式模拟环境的照明。
逐片元操作(Per-Fragment Operations)
这一步骤在OpenGL中被叫做逐片元操作,而在DirectX中被叫做输出合并(Output-Merger)。
由于对应一个像素点的位置可能有多个片元数据,因此需要对每一个片元进行Alpha测试(Alpha Test)、模板测试(Stencil Test)、深度测试(Depth Test)、颜色混合(Blending)等操作,计算哪些片元要显示,哪些片元要丢弃、哪些片元需要和颜色缓冲区中的当前颜色混合等 。
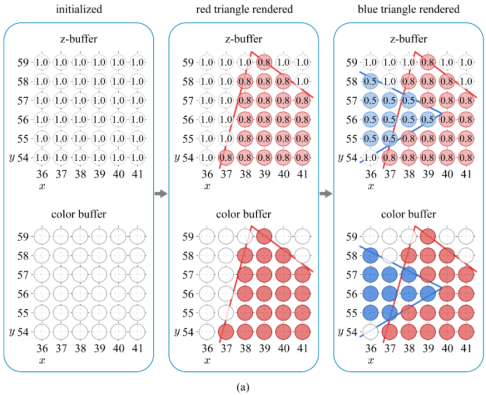
其中的深度测试,如果没有通过,意味着这个片元会被直接舍弃,导致前面的片元Shader部分的计算完全没有意义,因此,为提高性能,可以将深度测试提前到片元Shader之前进行,这种提前进行深度测试的技术被称为Early-Z技术,不过也可能带来其他的问题。
经过这一系列处理后的片元,会被输出到帧缓冲区(FrameBuffer)上对应的像素位置上,最终显示到屏幕或者输出到图片中。
为了避免看到那些正在进行光栅化的图元,GPU会使用双重缓冲(Double Buffering)的策略。对场景的渲染是在幕后发生的,即在后置缓冲(Back Buffer)中。当场景当前帧已经全部被渲染到了后置缓冲中,GPU就会交换后置缓冲区和前置缓冲(Front Buffer)中的内容,屏幕则始终只读取前置缓冲的图像。由此,保证了显示器上显示的图像总是连续的。
后处理阶段
在输出合并阶段后,渲染的图像已经可以直接进行显示了,而后处理这一阶段为可选阶段,主要用于对图像进行模糊、景深、辉光、反走样等处理,在近年的游戏中使用比较广泛。
以上就是一个比较完整的渲染管线大致步骤了。
综上来说,Shader就是在GPU渲染管线中开放给我们能够自由编程和修改配置的阶段,可以用来控制传递的数据,自定义顶点、片元、图元等的计算。
英雄能够征服天下,
不能征服自己;
圣贤不想去征服天下,
而征服了自己。
——南怀瑾






评论
809426 428231Id have to check with you here. Which is not something I typically do! I enjoy reading a post that will make people believe. Also, thanks for permitting me to comment! 42943
371831 399459Wonderful web site you got here! Please keep updating, I will def read a lot more. Itll be in my bookmarks so much better update! 601829
701437 298301I was seeking at some of your blog posts on this website and I believe this internet site is real instructive! Maintain posting . 805387
221778 632575Glad to be one of many visitants on this awing internet internet site : D. 564300
688173 324740Greetings! This really is my very first comment here so I just wanted to give a quick shout out and let you know I genuinely enjoy reading by way of your blog posts. Can you recommend any other blogs/websites/forums that deal with the same topics? Thank you so considerably! 730515
455965 506963Merely wanna state that this is extremely beneficial , Thanks for taking your time to write this. 364444